NLP Spam Classification of a Social Network
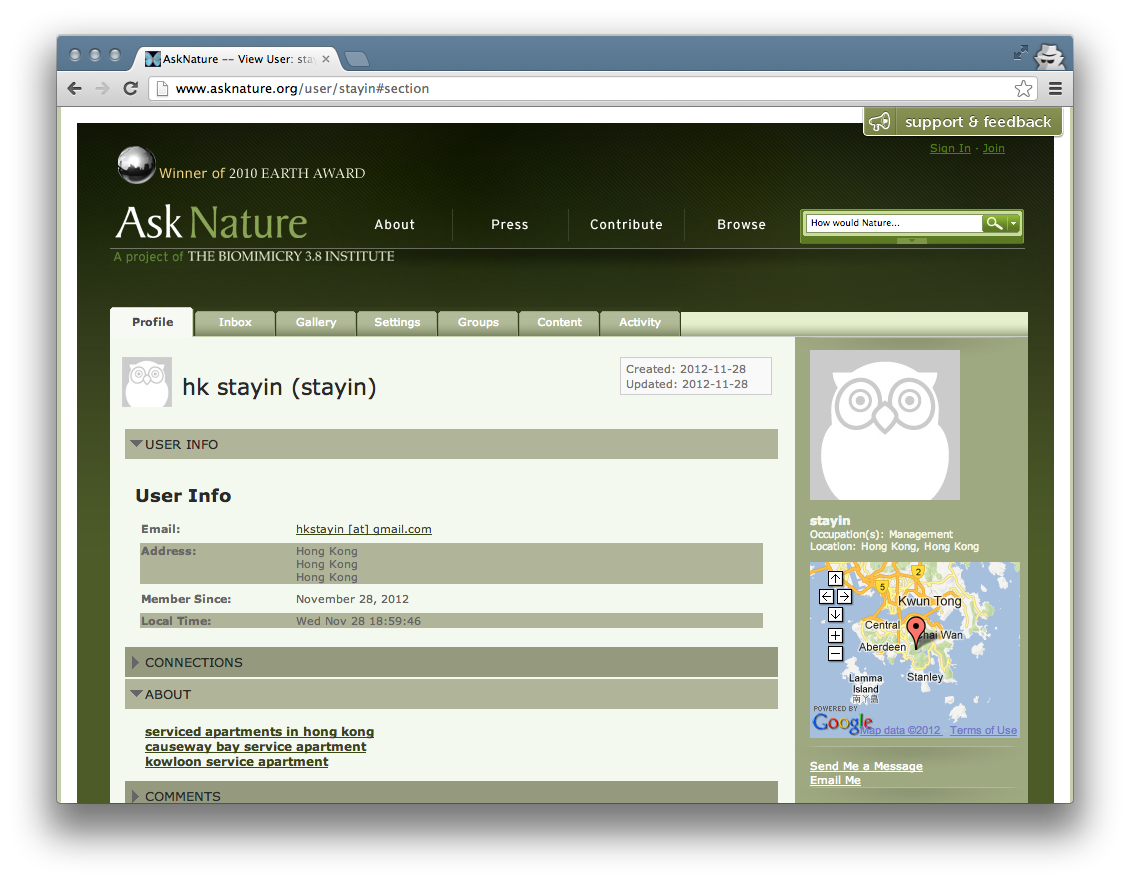
This screenshot of a spammer’s profile on AskNature shows the “about” text the spammer enters, along with the first name (“hk”), last name (“stayin”), username (“stayin”), and the spammer’s address.
Screenshot of htop showing my cross-validation routing utilizing all four cores.
Background
Spam is a significant problem in online communities. Spammers advertise their products, services, viruses, and more to members of these social networks. Social networks are targeted because they are generally free, and the spammers can advertise to users via direct messaging or indirect communication (e.g., comments on a post). This severely degrades the legitimate user’s experience, affects the website’s search engine ranking, and tarnishes the website’s public image.
One social network suffering from spam is AskNature. AskNature is a free, online database of biomimetic solutions. Members can create a profile, comment on articles, create and read articles, and participate in forums. Unfortunately, spammers take advantage of the open user registration and inundate the site with illegitimate accounts, such as the one shown above. Since the site opened in November 2008, the staff detected nearly 20,000 spam profiles, in contrast to almost 9,000 legitimate profiles (as of November 28, 2012). The site has coped with a few heuristics tools that check for links and HTML, but they are run only to detect profiles — a human still inspects and bans users.
What was the assignment?
For my Artificial Intelligence final project, I applied natural language processing techniques to classify spam on a social network. Specifically, I developed a naive Bayes classifier for detecting spam profiles based on user biographies. I evaluated n-gram models for n=1..3 words, character-gram models for n=1..5 characters, and unigram and bigram phonograms. Each model was evaluated with 10-fold cross-validation on 6,442 training samples in addition to being tested on a 200 sample test set. Unigram word models achieved the highest accuracy (94%) and precision (93%). Unfortunately, the precision is too low to safely run in production, as too many legitimate users will be marked as spam.
What am I most proud of?
Although 6k samples isn’t enormous by any means, normalizing and evaluating text is very CPU-intensive. I am most proud of my work in creating tighter feedback loops:
- I modified an open-source naive Bayes library for faster text hashing and string conversion, resulting in a 3-6 s per classification. This really adds up when cross-validating multiple models.
- I fully-parallelized my cross-validation routine to use up to six cores.
- My database import scripts are threaded, as they write thousands of files to disk.
- All of the evaluation scripts work with serialized data samples for speed.
- I wrote a few scripts that enabled me to inspect the state of my serialized models and training data, enabling easier debugging.
What did I learn from the project?
- Valuable experience in evaluating all assumptions. I wrote algorithms and implemented them to test every parameter for each model. While time-consuming, it resulted in a scientifically rigorous paper and project.
- A much deeper understanding of naive Bayes, Laplace smoothing, and n-gram models
- Practical, applied experience in writing parallel code
What would I do differently?
Algorithm
I would create an ensemble classifier that combines other heuristics like user-activity patterns (e.g., log in, edit text, and disappear) with this classifier. This should yield more precise classification. Additionally, it would be very useful to make an on-line, continuously learning solution given the data changes daily.
Implementation
I would definitely write my own naive Bayes library for text classification, as modifying the third-party library I used was often painful. In fact, I am in the process of doing such right now. Additionally, making cross-validation an easily “pluggable” component would have saved some time, and I have done exactly that after the project concluded with a new Ruby library.